 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPT Fusion: Pyramid Patch Transformerfor a Case Study in Image Fusion
Jul 29, 2021

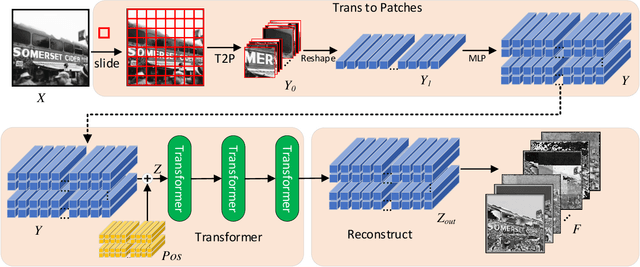
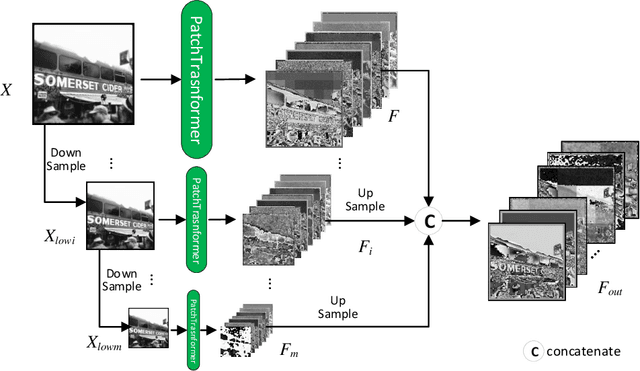
The Transformer architecture has achieved rapiddevelopment in recent years, outperforming the CNN archi-tectures in many computer vision tasks, such as the VisionTransformers (ViT) for image classification. However, existingvisual transformer models aim to extract semantic informationfor high-level tasks such as classification and detection, distortingthe spatial resolution of the input image, thus sacrificing thecapacity in reconstructing the input or generating high-resolutionimages. In this paper, therefore, we propose a Patch PyramidTransformer(PPT) to effectively address the above issues. Specif-ically, we first design a Patch Transformer to transform theimage into a sequence of patches, where transformer encodingis performed for each patch to extract local representations.In addition, we construct a Pyramid Transformer to effectivelyextract the non-local information from the entire image. Afterobtaining a set of multi-scale, multi-dimensional, and multi-anglefeatures of the original image, we design the image reconstructionnetwork to ensure that the features can be reconstructed intothe original input. To validate the effectiveness, we apply theproposed Patch Pyramid Transformer to the image fusion task.The experimental results demonstrate its superior performanceagainst the state-of-the-art fusion approaches, achieving the bestresults on several evaluation indicators. The underlying capacityof the PPT network is reflected by its universal power in featureextraction and image reconstruction, which can be directlyapplied to different image fusion tasks without redesigning orretraining the network.
Multiple Riemannian Manifold-valued Descriptors based Image Set Classification with Multi-Kernel Metric Learning
Aug 06, 2019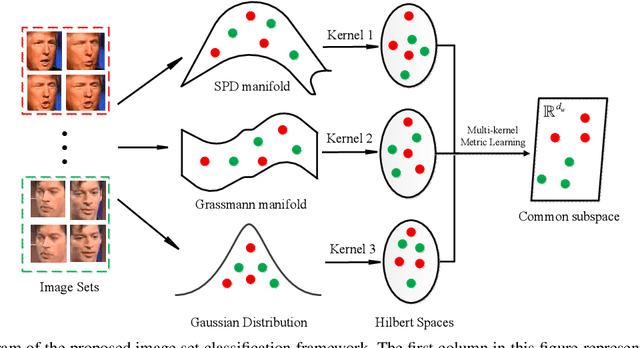



The importance of wild video based image set recognition is becoming monotonically increasing. However, the contents of these collected videos are often complicated, and how to efficiently perform set modeling and feature extraction is a big challenge for set-based classification algorithms. In recent years, some proposed image set classification methods have made a considerable advance by modeling the original image set with covariance matrix, linear subspace, or Gaussian distribution. As a matter of fact, most of them just adopt a single geometric model to describe each given image set, which may lose some other useful information for classification. To tackle this problem, we propose a novel algorithm to model each image set from a multi-geometric perspective. Specifically, the covariance matrix, linear subspace, and Gaussian distribution are applied for set representation simultaneously. In order to fuse these multiple heterogeneous Riemannian manifoldvalued features, the well-equipped Riemannian kernel functions are first utilized to map them into high dimensional Hilbert spaces. Then, a multi-kernel metric learning framework is devised to embed the learned hybrid kernels into a lower dimensional common subspace for classification. We conduct experiments on four widely used datasets corresponding to four different classification tasks: video-based face recognition, set-based object categorization, video-based emotion recognition, and dynamic scene classification, to evaluate the classification performance of the proposed algorithm. Extensive experimental results justify its superiority over the state-of-the-art.
Pose Invariant 3D Face Reconstruction
Nov 13, 2018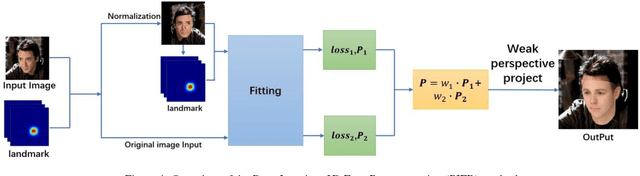
3D face reconstruction is an important task in the field of computer vision. Although 3D face reconstruction has being developing rapidly in recent years, it is still a challenge for face reconstruction under large pose. That is because much of the information about a face in a large pose will be unknowable. In order to address this issue, this paper proposes a novel 3D face reconstruction algorithm (PIFR) based on 3D Morphable Model (3DMM). After input a single face image, it generates a frontal image by normalizing the image. Then we set weighted sum of the 3D parameters of the two images. Our method solves the problem of face reconstruction of a single image of a traditional method in a large pose, works on arbitrary Pose and Expressions, greatly improves the accuracy of reconstruction. Experiments on the challenging AFW, LFPW and AFLW database show that our algorithm significantly improves the accuracy of 3D face reconstruction even under extreme poses .
L1-2PCANet: A Deep Learning Network for Face Recognition
May 26, 2018In this paper, we propose a novel deep learning network L1-(2D)2PCANet for face recognition, which is based on L1-norm-based two-directional two-dimensional principal component analysis (L1-(2D)2PCA). In our network, the role of L1-(2D)2PCA is to learn the filters of multiple convolution layers. After the convolution layers, we deploy binary hashing and block-wise histogram for pooling. We test our network on some benchmark facial datasets YALE, AR, Extended Yale B, LFW-a and FERET with CNN, PCANet, 2DPCANet and L1-PCANet as comparison. The results show that the recognition performance of L1-(2D)2PCANet in all tests is better than baseline networks, especially when there are outliers in the test data. Owing to the L1-norm, L1-2D2PCANet is robust to outliers and changes of the training images.